

IT operations groups, web site reliability engineers (SREs) and repair suppliers are on a mission to scale throughout geographies, broaden their digital companies and create new experiences for purchasers. Amid this drive, their backend IT methods are getting extra complicated. This hinders visibility into purposes and makes monitoring and troubleshooting cumbersome. With heightened competitors available in the market, companies can’t afford to take hits on income or buyer expertise scores on account of points stemming from their IT stack, equivalent to unknown outages, elevated incident administration occasions and knowledge replication.
Infusing synthetic intelligence capabilities into IT operations (AIOps) can elevate effectivity by automation, enhance safety and make a major affect in keeping off downtime. AIOps makes use of machine studying (ML) to boost IT operations equivalent to efficiency monitoring, occasion correlation and evaluation. With AIOps, IT groups, SREs and repair suppliers can predict and forestall outages earlier than they happen and resolve them mechanically. Furthermore, AIOps makes use of ML to research present and previous knowledge to make exact predictions, decreasing prices and rushing up return on funding (ROI).
AIOps Implementation
Launching AIOps requires a singular strategy relying in your group, its capabilities and desires. This text gives a three-step implementation technique to assist your group detect incidents earlier than they affect customers, automate responses and forestall recurring points.
Fig: AIOps implementation strategy
With the superior capability to gather and analyze IT operational knowledge, AIOps is an asset for a variety of actions and options. When applied successfully, AIOps can allow IT groups, SRES and repair suppliers to considerably scale back software outage prices by over 60% inside a span of 24 months.
Getting Began With AIOps: Predicting Outages in Functions and Infrastructure
The AIOps platform will be leveraged by IT groups, SREs and repair suppliers for knowledge gathering, evaluation and era of helpful insights. It’s designed to boost operational effectivity, provide predictive alerts, scale back mean-time-to-identify (MTTI) and mean-time-to-repair (MTTR) in addition to stop service outages.
Suggestions
- Prioritize onboarding mission-critical purposes, equivalent to community monitoring, fault administration and repair assurance onto the AIOps platform.
- Decide the most effective methodology to ingest knowledge from the completely different monitoring instruments. For instance, construct APIs, use pre-built connectors, use MuleSoft to mechanically gather knowledge from completely different methods, and so on.
- Select the suitable ML mannequin based mostly on the varieties of uncooked knowledge, e.g., use an anomaly detection mannequin to determine points from a dataset or use a time-series mannequin to grasp patterns based mostly on historic knowledge.
- Use closed-loop automation to resolve low-risk points; for instance, automate disk clean-up points or Java Digital Machine (JVM) bounce for JVM-related points.
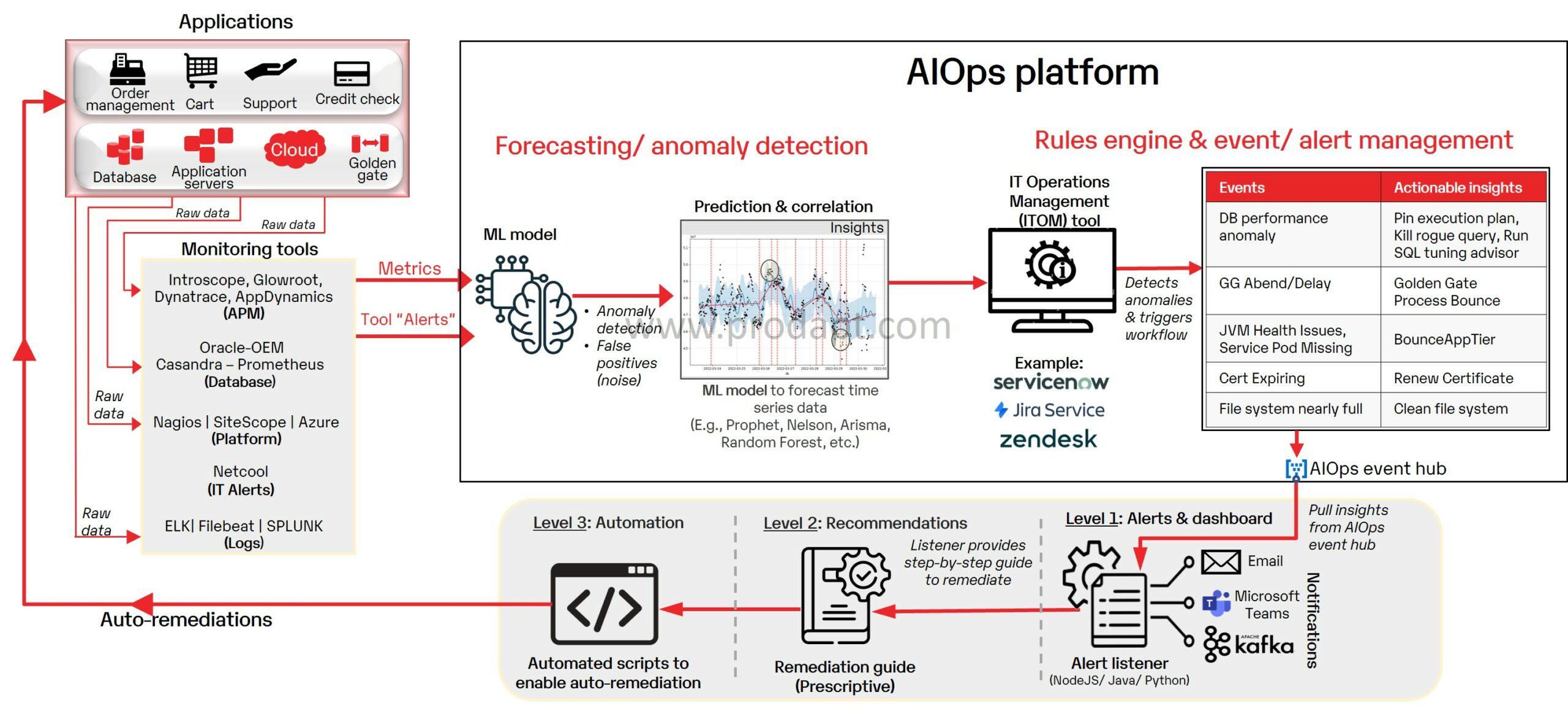
Fig: AIOps platform
Assess Your Group’s Adoption of AIOps to Acquire Worth
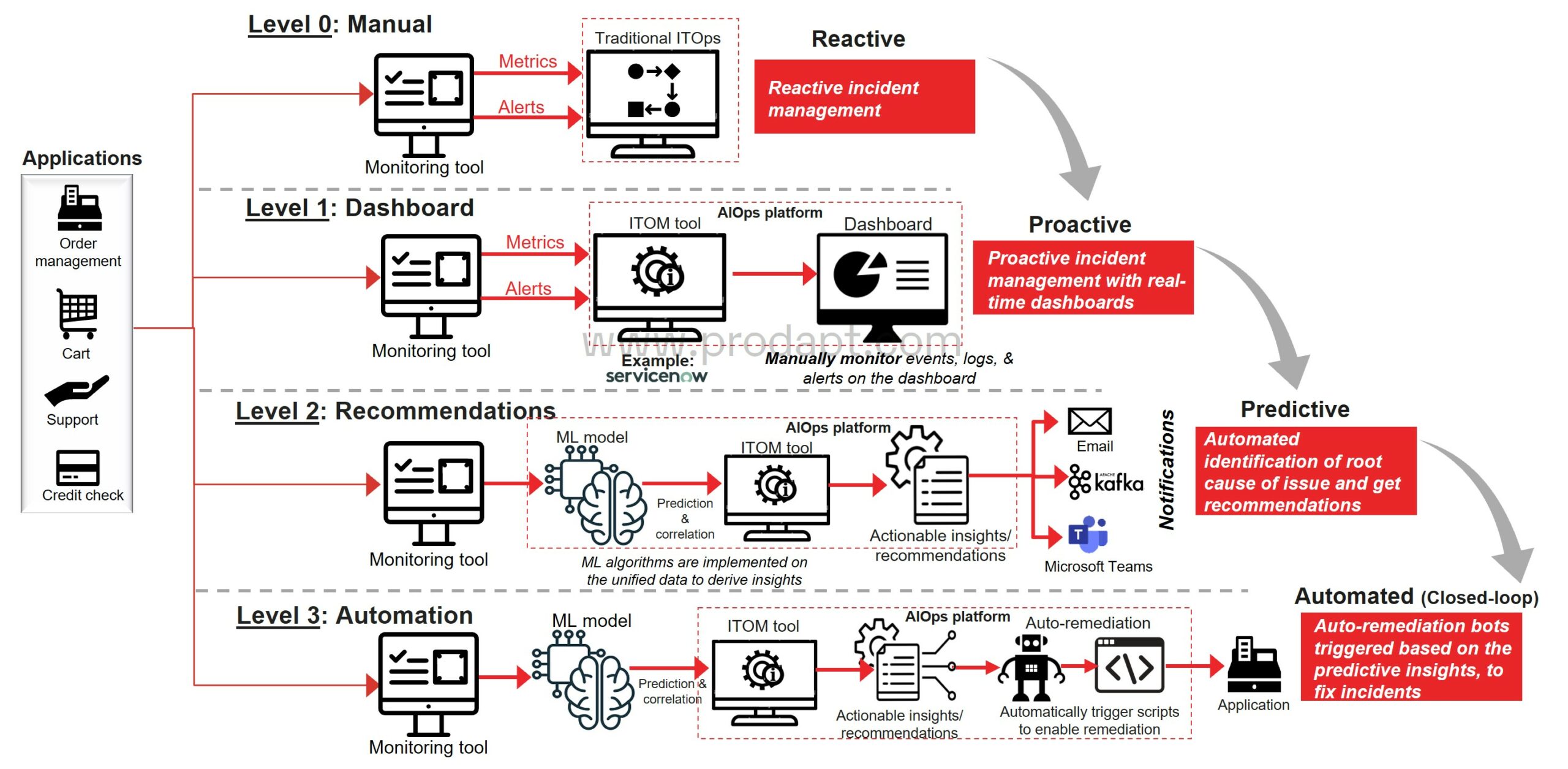
Organizations considering AIOps as a technique ought to first consider their present maturity after which chart out a path to make the most effective use of AIOps, which is automated decision. There are three ranges of maturity in AIOps adoption.
Suggestions
Degree 1: Dashboard
- Take away operational siloes by integrating the applying knowledge sources into unified structure and ITOM instrument.
- Acquire logs from purposes and arrange alerts which can be commissioned to command facilities to escalate as per the outlined SOPs.
Degree 2: Alarm & Suggest
- Implement supervised or unsupervised ML algorithms on the unified knowledge to derive insights.
- De-duplicate and correlate alerts and occasions by noise discount to alleviate alert fatigue
Degree 3: Automation
- Correlate incidents and occasions with enterprise impacts by leveraging ML algorithms.
- Set off autonomous remediation bots spontaneously based mostly on the predictive insights to repair incidents which can be more likely to occur in operations.
Determine Functions for the AIOps Platform
Conduct an AIOps workshop with key stakeholders to slim down the checklist of apps and prioritize them for analysis. Apply particular standards to prioritize purposes that meet the required onboarding requirements.
Suggestions
- Prioritize onboarding important apps and outage-causing apps on the AIOps platform.
- Tag the info e.g., metrics, logs, stock, topology, to ease the shopping, looking out and visualization of knowledge throughout the distributed analytics repository.
- Setup an AIOps service and help workforce, as there’s a fixed want to take care of and replace the platform options
- Acquire all related logs, metrics and traces together with knowledge collected from ITOM platforms. A poorly constructed AIOps platform will present incorrect insights and inaccurately mirror the actions within the IT surroundings.
Onboard Functions and Leverage AI to Predict and Resolve Points
To provoke software onboarding, monitoring instruments have to be set as much as gather knowledge for ML fashions. Predictions from the fashions will be built-in into visible dashboards for evaluation.
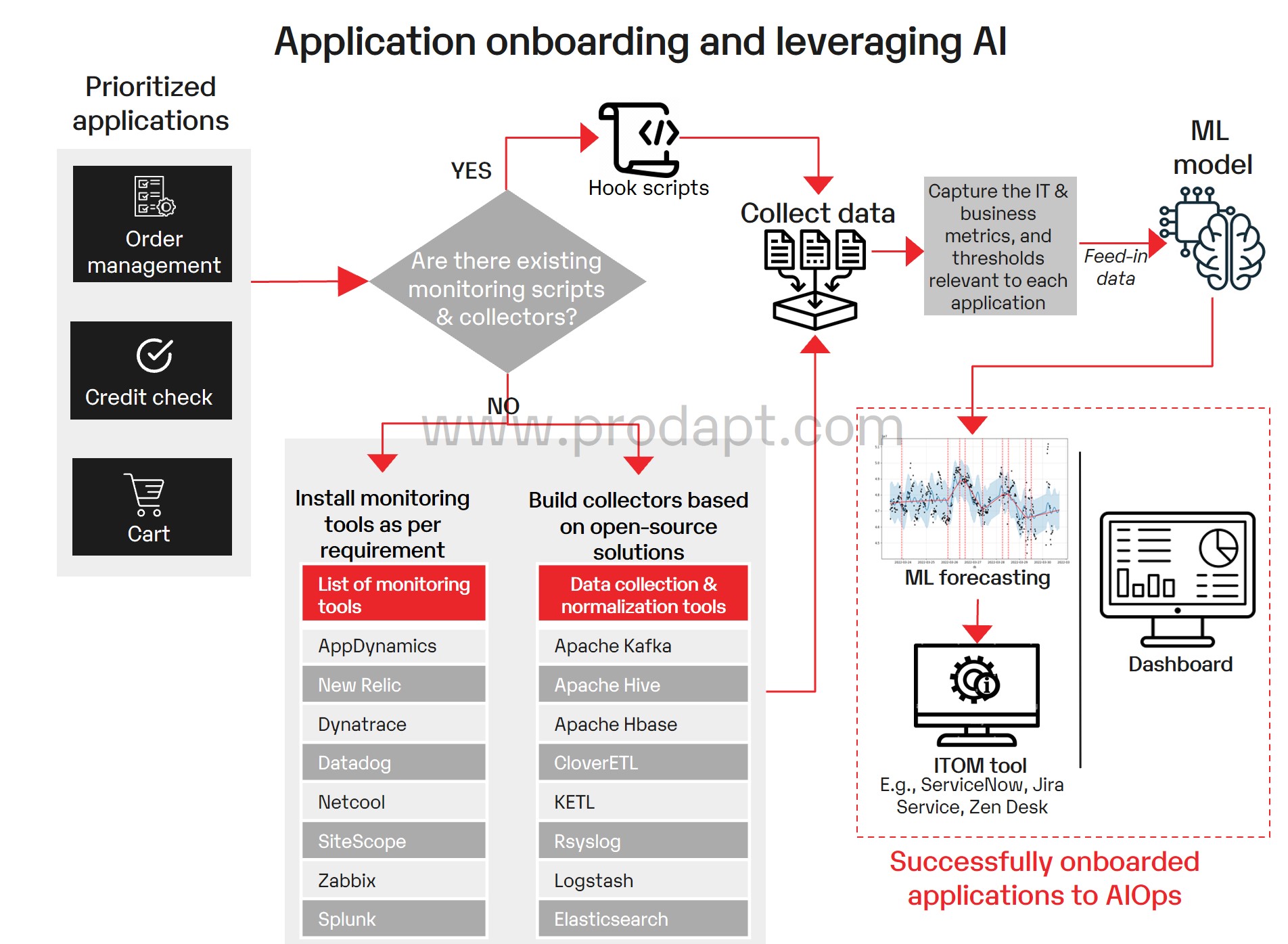
Fig: Utility onboarding
Suggestions
- Route each the on-premises and cloud-centric knowledge to the AIOps platform. This can facilitate the prediction of points in each the environments.
- Use ML fashions equivalent to Prophet, Nelson, Arisma, Random Forest, and so on., to forecast the time sequence knowledge, correlate the occasions and predict thresholds.
- Select safe connectors to switch knowledge in/out of the AIOps platform. As an illustration, any log flowing into the platform have to be despatched over transport layer safety (e.g., syslog) or HTTPS (API endpoints).
By implementing AIOps, service suppliers can efficiently scale back the MTTI and MTTR, attaining a 63% discount in outage prices for purposes inside 24 months, a 90% discount in false-positive alerts and a 400+ hours discount in downtime each year.
Ramesh Ram (Assistant Vice President), Sreedhar S Okay (Affiliate Director), Sakthivel D (Director), and Rohit Karthikeyan (Supervisor) additionally contributed to this text.